Textual Data Representation
Lab: Basics of Digitizing Data
Video Runtime: 08:47
When you write “WordPress Rocks,” the computer needs a way to understand each of the characters. In this episode, you will learn how textual data is represented in the computer. We need a way to encode text into a format that computers understand. Let’s talk about ASCII and unicode character sets.
Your takeaways from this episode are:
- Human-readable string data is a representation of binary
- ASCII uses 8-bit
- Unicode uses 8 or 16-bit and is flexible for more bits
- Unicode is for international use
- Encoding is a technique to reduce memory footprint
Study Notes
Now, you are going to learn American Standard Code for Information Interchange (ASCII) and how to convert that into binary.
When we write alphanumeric or textual data in our code, how is that “string” type represented in the computer circuits? How does it become binary?
You know that computer circuits require 1s and 0s, binary. Therefore, in our software languages, how is it that we are able to write human readable textual data and then that information is converted into the 1s and 0s?
What symbol pattern is used?
ASCII or Unicode Character Set
A symbol code pattern is required. This maps the presentation that we work with in human readable format. What symbol pattern is used?
ASCII or Unicode character set is used.
What is ASCII?
- Character set
- Originally it was 7-bit binary, which gave us 128 unique characters.
- The current standard is 8-bit (1 byte)
- 256 unique characters
- Latin-1 Extended ASCII character set
For more information see ASCII.
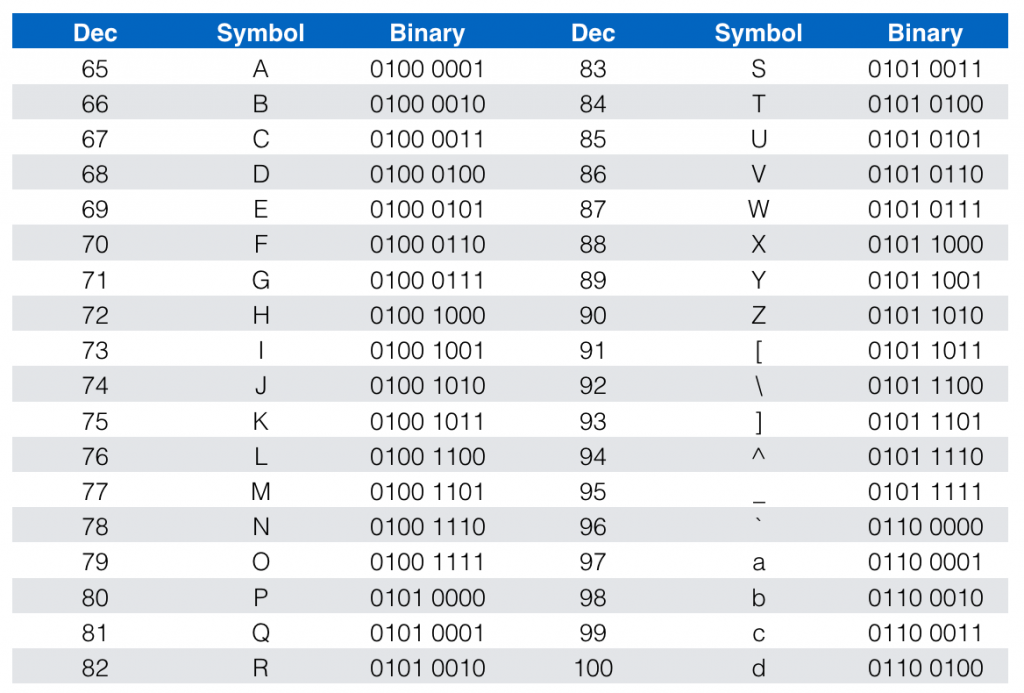
These tables show only a sample of how the symbol represents the corresponding 8-bit binary. For example, a capital P is binary 0101 0000. Let’s see how our page title breaks down into binary.
You should appreciate that the computer understands the binary. Therefore, every symbol is a representation of the 8-bit binary. Imagine coding all day long at this level versus the human-readable code that we are used to. Imagine how slow and error prone this level of coding would be.
Simple ASCII Exercise
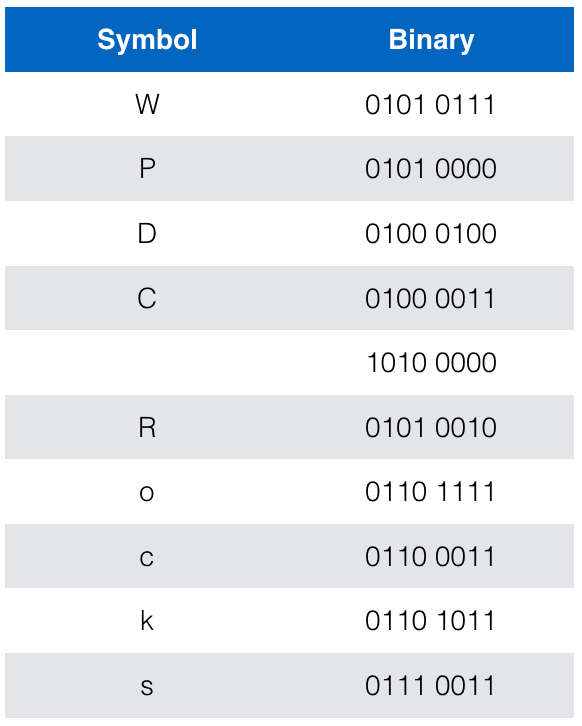
- Go to http://www.ascii-code.com
- Decode character by character
- Include the space as that’s a symbol too
Unicode Character Set
- For international use
- Character set
- 16-bit (2 bytes) per character
- Flexible to add additional bits when needed
- Superset to ASCII
- One example is found here http://unicode.org/charts/
ASCII is fine for English. However, many languages have different characters, each of which requires data representation. The Unicode character set provides an international use.
WordPress uses ‘utf8’ for the database character set. UTF-8 is a Unicode character encoding. It is 8-bit to be backward compatible with ASCII.
As these characters consume a lot of memory, encoding is a way of reducing the space. There are many different encoding techniques, all of which are currently beyond the scope of this course.
Practical Uses
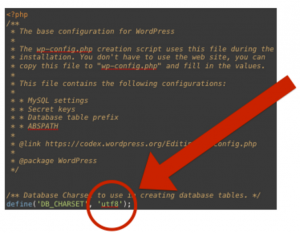 ‘utf8’ is a Unicode character encoding for the database
‘utf8’ is a Unicode character encoding for the database
8-bit to be backward compatible with ASCII
WordPress uses ‘utf8’ for the database character set. UTF-8 is a Unicode character encoding. It is 8-bit to be backward compatible with ASCII.
There’s a time to code and …. yup, that sums it up.
Episodes
Total Lab Runtime: 02:59:07
- 1 Lab Introductionfree 03:56
- 2 Electronics “on” and “off” Statesfree 12:11
- 3 Symbol to Represent Quantityfree 14:26
- 4 Number System for Statefree 12:44
- 5 Binary – Combining 1s and 0sfree 19:25
- 6 Improving Binary Representationfree 13:45
- 7 The Age of 16 Bit and Hexadecimalfree 15:15
- 8 Binary Additionfree 03:59
- 9 Negative Integer Data Representation - Part 1free 10:06
- 10 Negative Integer Data Representation - Part 2free 18:42
- 11 Real Number Data Representation - Part 1free 17:12
- 12 Real Number Data Representation - Part 2free 10:18
- 13 Textual Data Representationfree 08:47
- 14 Digital Image Data Representationfree 18:21
